各位早安,書接上回我們學會透過發送 cookie 來繞過18歲守門員,今天我們要學習如何翻頁繼續爬
在這裡的大家一定都很有愛心 所以今天的目標是PTT的寵物領養版
我們要看更多頁才能找到適合我們的領養對象 所以今天來實作翻頁功能
首先打開PTT的寵物領養版網頁 按下 F12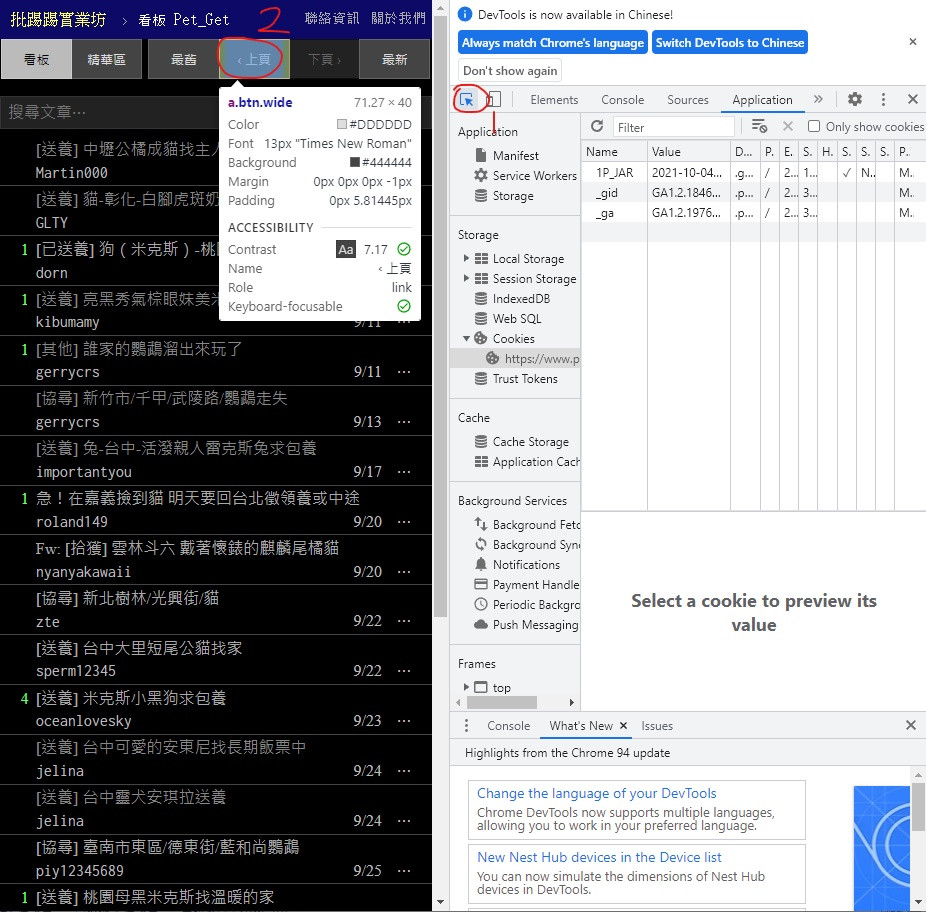
照著標示順序按
1號位置是按了之後點網頁的內容就會帶你去找他的原始碼部分
可以看到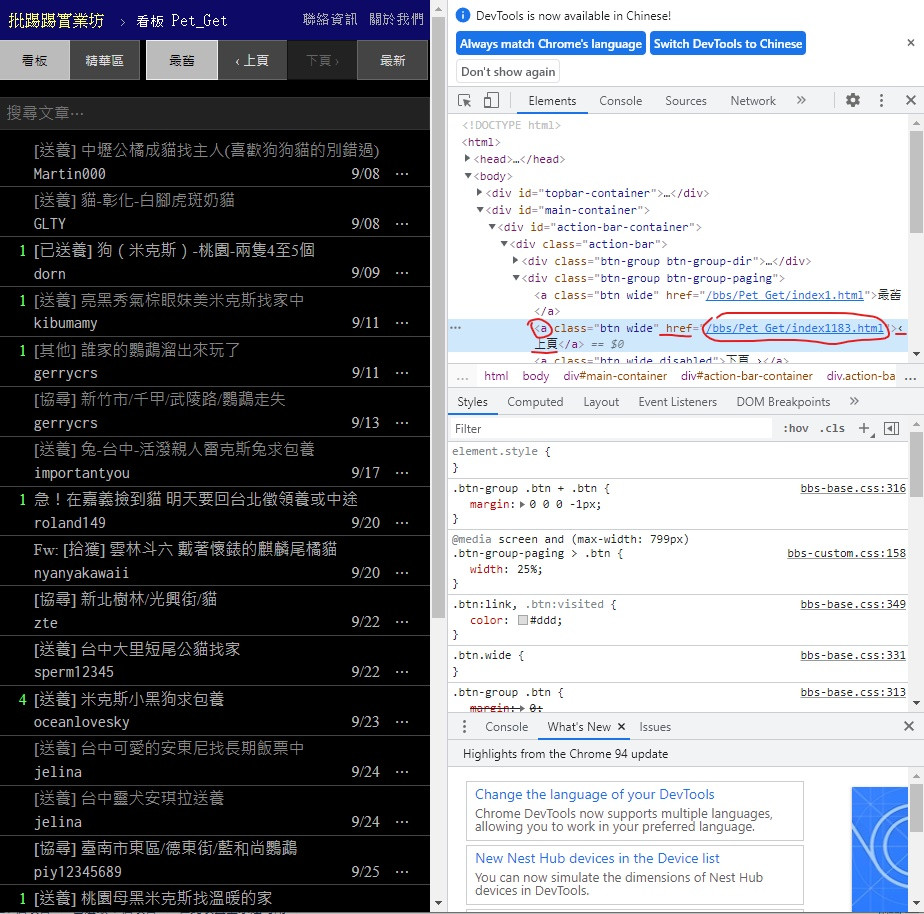
標籤為 < a > class = "btn wide" 文字則是 ‹ 上頁
href 後面的則是 url 也就是我們要的上一頁連結
接著左鍵雙擊 ‹ 上頁 的部分複製它
其他部分也可以用一樣方式複製 貼到程式碼內
在下面加上
prePage = data.find("a", class_ = "btn wide", text = "‹ 上頁")
newUrl = prePage["href"]
print("https://www.ptt.cc"+newUrl)
先建立 prePage 存放抓到的資訊 指定的邏輯剛剛已經有展示怎麼找到的
建立 newUrl 用來存放我們的目標 也就是 href 的連結部分
但注意這個連結並不完整 觀察原本網址缺啥後加進去
最後印出來
執行看看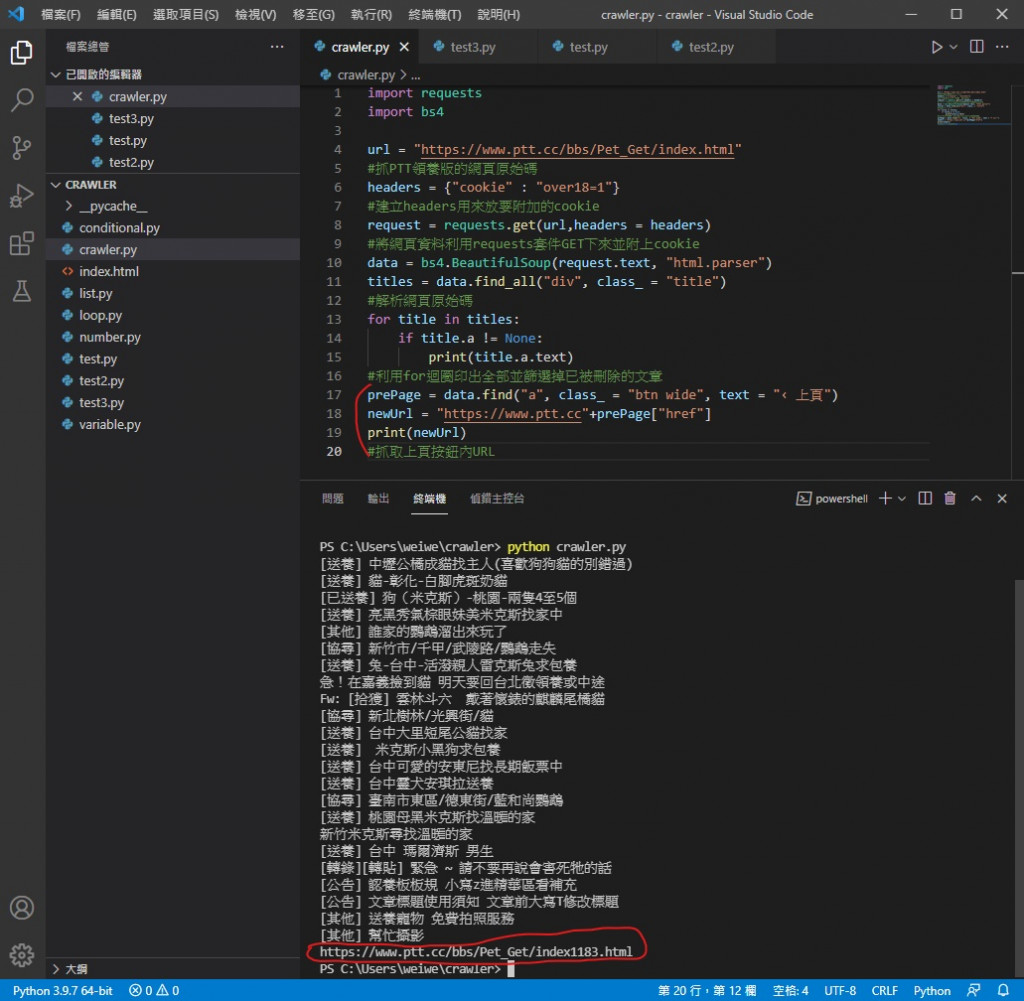
可以看到 newUrl 已經是下一頁的完整網址了
目前程式碼
mport requests
import bs4
url = "https://www.ptt.cc/bbs/Pet_Get/index.html"
#抓PTT領養版的網頁原始碼
headers = {"cookie" : "over18=1"}
#建立headers用來放要附加的cookie
request = requests.get(url,headers = headers)
#將網頁資料利用requests套件GET下來並附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析網頁原始碼
for title in titles:
if title.a != None:
print(title.a.text)
#利用for迴圈印出全部並篩選掉已被刪除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上頁")
newUrl = "https://www.ptt.cc"+prePage["href"]
print(newUrl)
#抓取上頁按鈕內URL
那得到這個網址能幹嘛
答案是可以套入上面的程式碼再跑一次 就能獲得另一頁的內容
那我們難道要把上面得程式碼全部複製貼上一次嗎
不用 只要把我們剛剛寫出來的程式碼定義成函式就可以再次叫出來用
被定義完的函式只要呼叫到它便會執行一次裡面的程式碼
利用這個特性便可以多次進行爬取的動作
作法如下
把 url 變數移到最下面
在空出來的位置打上 def getData(url): 意思是定義函式 getData 用到它時要傳給它 url
接著把底下的功能全選 (不包括 url 變數的建立) 並按下 TAB 進行縮排
使其歸到 def getData(url): 的裡面
最後加上
return newUrl 用來回傳 newUrl 出去 並刪掉多餘的 print(newUrl)
改完的程式碼
import requests
import bs4
def getData(url):
headers = {"cookie" : "over18=1"}
#建立headers用來放要附加的cookie
request = requests.get(url,headers = headers)
#將網頁資料利用requests套件GET下來並附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析網頁原始碼
for title in titles:
if title.a != None:
print(title.a.text)
#利用for迴圈印出全部並篩選掉已被刪除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上頁")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上頁按鈕內URL
return newUrl
#回傳newUrl出去
url = "https://www.ptt.cc/bbs/Pet_Get/index.html"
#抓PTT領養版的網頁原始碼
print(getData(url))
實際執行情況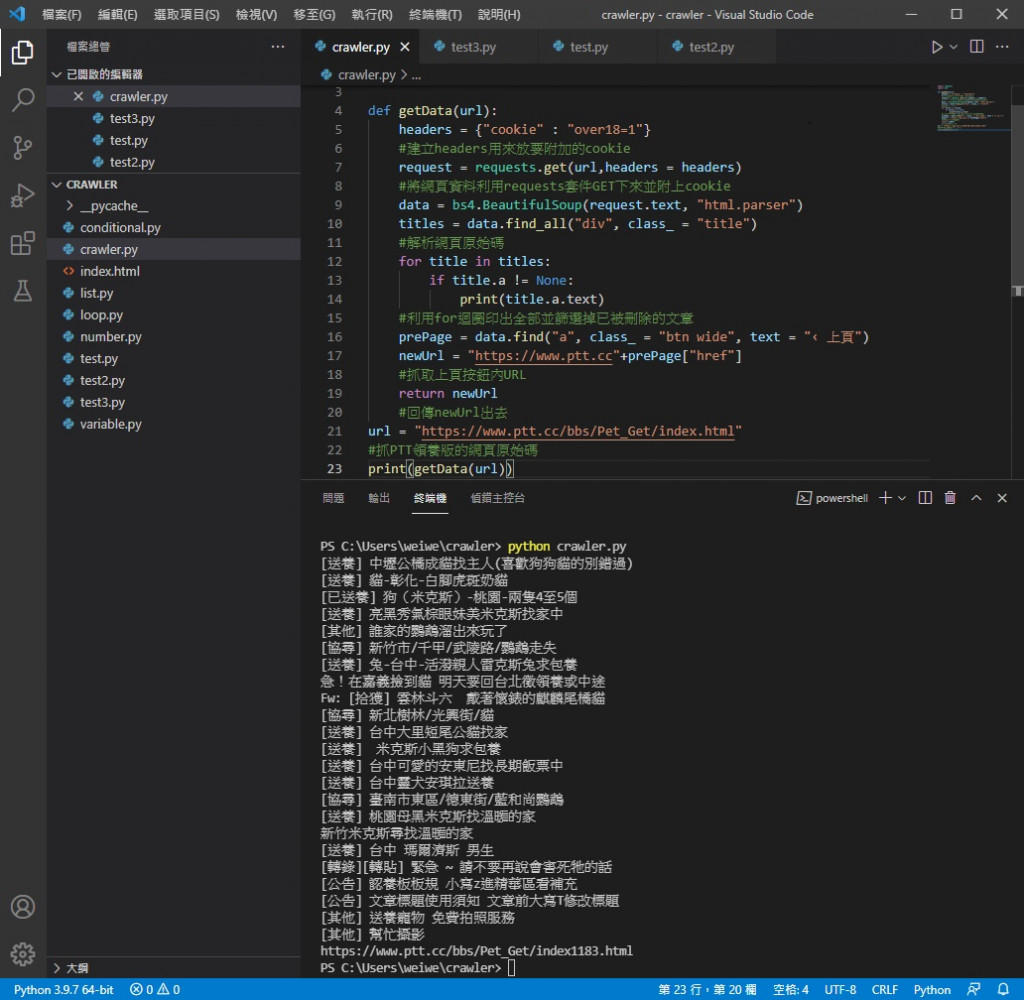
可以看到改完沒問題
接下來如何利用它翻頁呢
很簡單 加一個迴圈
把 print(getData(url)) 刪掉
改成
for i in range(1,4,1):
url = getData(url)
假設要爬三頁 設定迴圈三次 (想爬更多次就改迴圈次數)
這裡的 getData(url) 就是最後 return 出來的 newUrl
把回傳的 newUrl 放進 url 變數裡進行下一次回圈
實際執行看看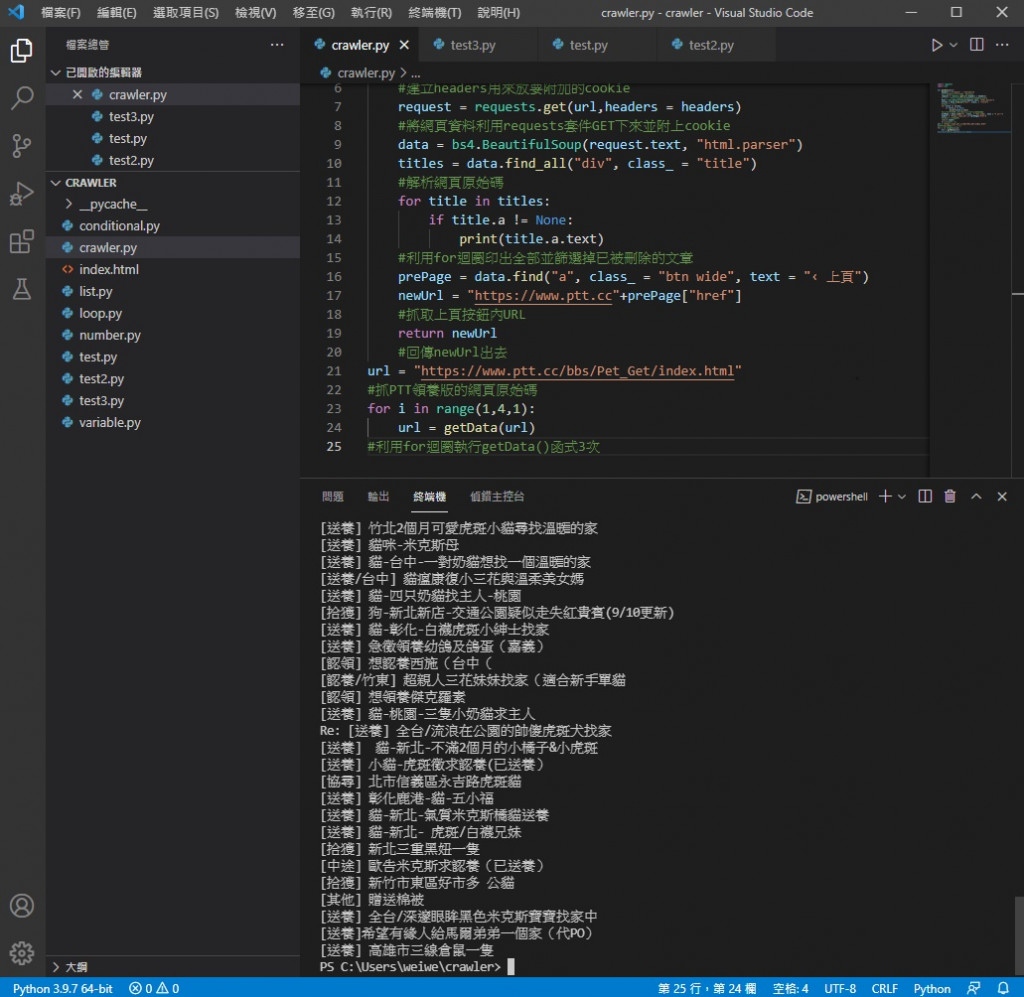
可以看到是三頁的標題量 執行時應該會頓兩下
原因是每次執行 getData( ) 都是重新對網站進行連線及抓取
所以才會有回應時間
今天我們成功翻頁了 看到更多頁就有更大機會找到適合領養的動物
明天我們要來小小優化一下這隻程式 讓它更方便使用
參考資料
https://www.youtube.com/watch?v=BEA7F9ExiPY&list=PL-g0fdC5RMboYEyt6QS2iLb_1m7QcgfHk&index=21
我們的記憶其實也經過大腦的後製喔
你還相信自己的記憶嗎還是不願再被大腦騙了呢

